The Harness is the Moat

Many companies have pressure to do something with AI. Most have started to give out licenses to their employees and experimented with an IT-sourced RAG at this point. Some are running pilots, and a select few are well on their way to create interesting new value propositions. Without core AI capability in-house it's hard to do the latter, that's what I want to address here today. Classic build/buy/partner logic states that you should partner when the capability is complex, moves fast, and you don't have a dedicated engineering team to own it:
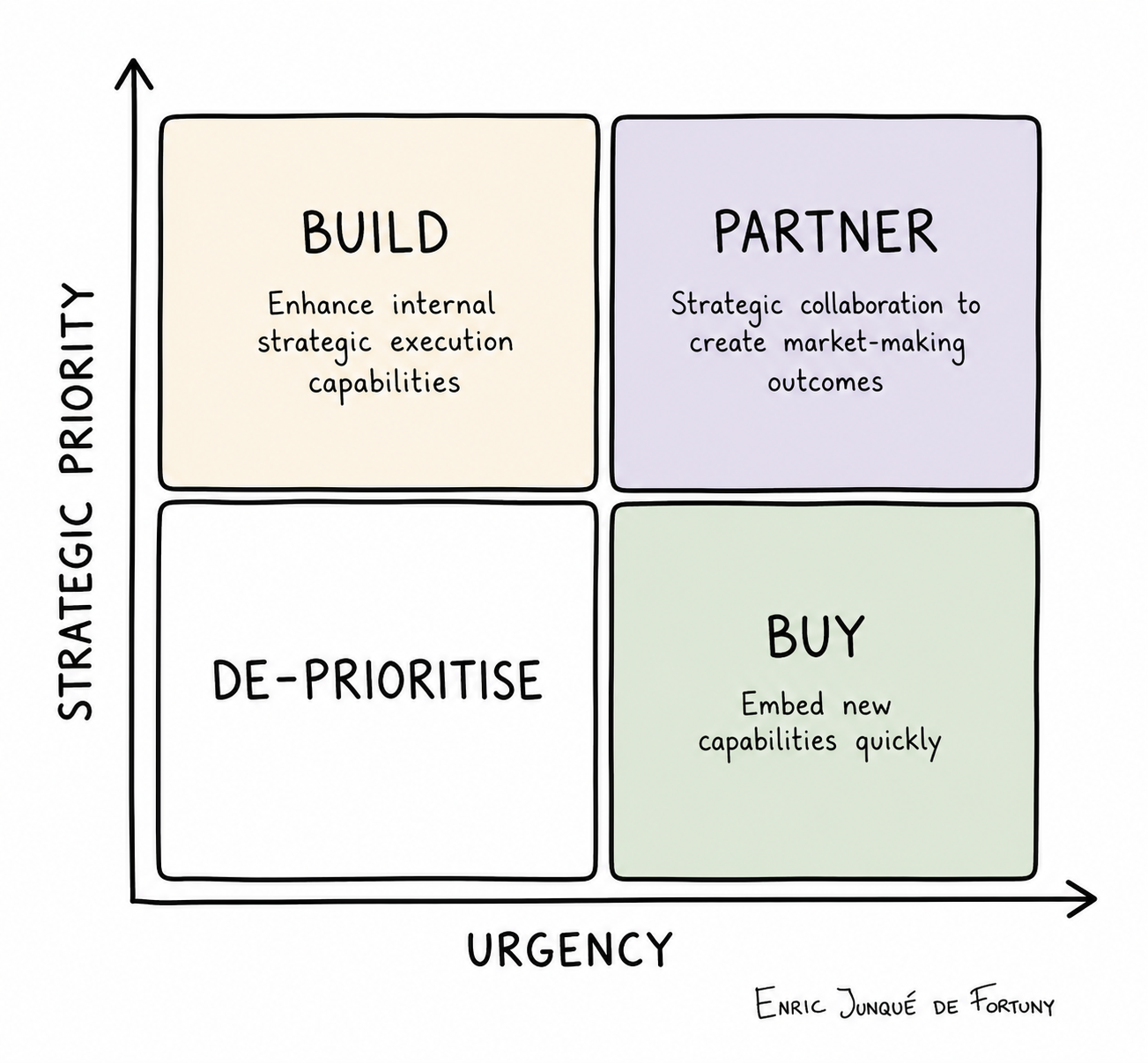
Let's use the legaltech space as a running example. It's not a core capability for law firms to do AI development, yet many are testing the waters. Many firms now use AIaaS companies like Harvey or Legora. Harvey currently sits at a $11B valuation, $195M ARR, 100,000 lawyers across the majority of the AmLaw 100. Legora, it's closest competitor is at $5.6B valuation, $100M ARR, 1,000 firms across 50 markets. So a combined, $16.6B in implied value built in under four years!
Still ... a question looms: is it the smart thing to do hand out AI ops to a 3rd party? How should we think about this decision?
Data flywheels are breaking down
In traditional machine learning (the non generative kind), data is a key source of competitive value. No data = no model = no AI. But what's different about GenAI is that the models are so good at almost any tasks that little data is needed to get them to say useful thinks about your specific use-cases (the technical term is to say prompt engineering replacing traditional transfer learning).
Based on this logic, when legal AI procurement lands on the GC's desk, the questions that get asked are:
- Will the vendor train AI models on our client documents?
- Will our data be retained after the session ends?
- Could another firm's lawyers see what we're working on?
So with those questions, both Harvey and Legora are clear: no training on client data. Customer-controlled retention periods, including zero-day options. Strict workspace isolation. The contracts enforce these through subprocessor obligations and audit rights.
Why are these they relinquishing their data flywheels so easily? A first part of the answer lies in the fact that they have actually tried to gather data at some point to build their own models, and failed. In May 2025, Harvey announced it was scrapping its proprietary legal AI model. Within 12 months of building it, 7 frontier models had outperformed Harvey's system on Harvey's own benchmark (BigLaw Bench).
After this failure, Harvey kept BigLaw Bench (the eval). Kept the 25,000 workflows (the pipeline). And simply plugged in new client data and a better model. This points at the key insight here: neither the model nor the client data are what survived in 2026.
Not all data is the same
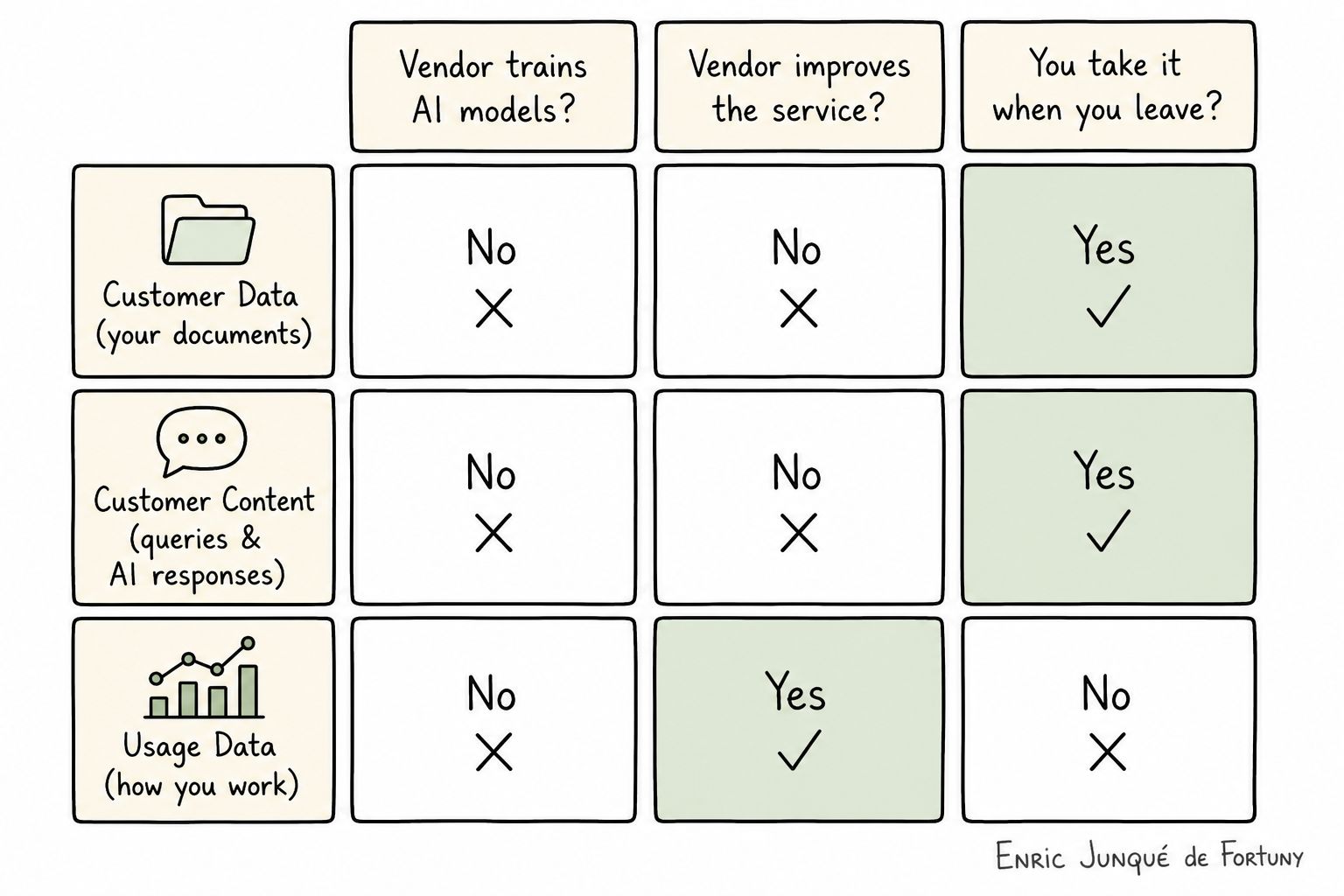
We have to be a bit more precise about data here. Both Harvey and Legora distinguish precisely between what you upload (your documents), what you generate (your queries and the AI's responses), and everything about how you use the platform. That third category has a name: Usage Data and it's something we usually don't mind giving out as much.
The matrix below describes the contractual (not technical!) situation. That is, Harvey and Legora could - in theory - train on your documents. but their terms say they won't.
Harvey's definition, verbatim, from Section 12.34 of their Platform Agreement:
"Usage Data" means information reflecting the access, interaction, or use of the Service by or on behalf of Customer including frequency, duration, volume, features, functions, visit, session, click through or click stream data, and statistical or other analysis, information, or data based on, or derivative works of, the foregoing.
And what Harvey can do with it, Section 11.7:
Harvey may collect and use Usage Data to develop, improve, support, and operate the Service.
Legora's definition, from Section 8.3.2 of their US General Terms:
"Legora may collect Usage Data to develop, improve, support and operate its Services."
Usage Data captures how you work. Which workflows do you run, in what sequence, at what volume? Where do your lawyers iterate versus accept the first output? Which features do they combine? Which tasks do they abandon halfway through? Where does the 50-step due diligence process break down, and where does it fly? Harvey has a telemetry pipeline exporting to Snowflake. They track "detailed accounting of every prompt and output token consumed." At 400,000 agentic queries per day across 1,300 organisations, they're building the largest dataset of legal workflow execution patterns in existence.
There is a second mechanism. Roughly 10% of Harvey's workforce are ex-BigLaw attorneys — from White & Case, Latham, Skadden, Paul Weiss — embedded inside client firms to design and build workflows. They are Harvey employees and the legal equivalent of Forward Deployment Engineers . The workflows they help create live on Harvey's platform, generate Usage Data for Harvey, and improve Harvey's harness even more using the perfect feedback loop!
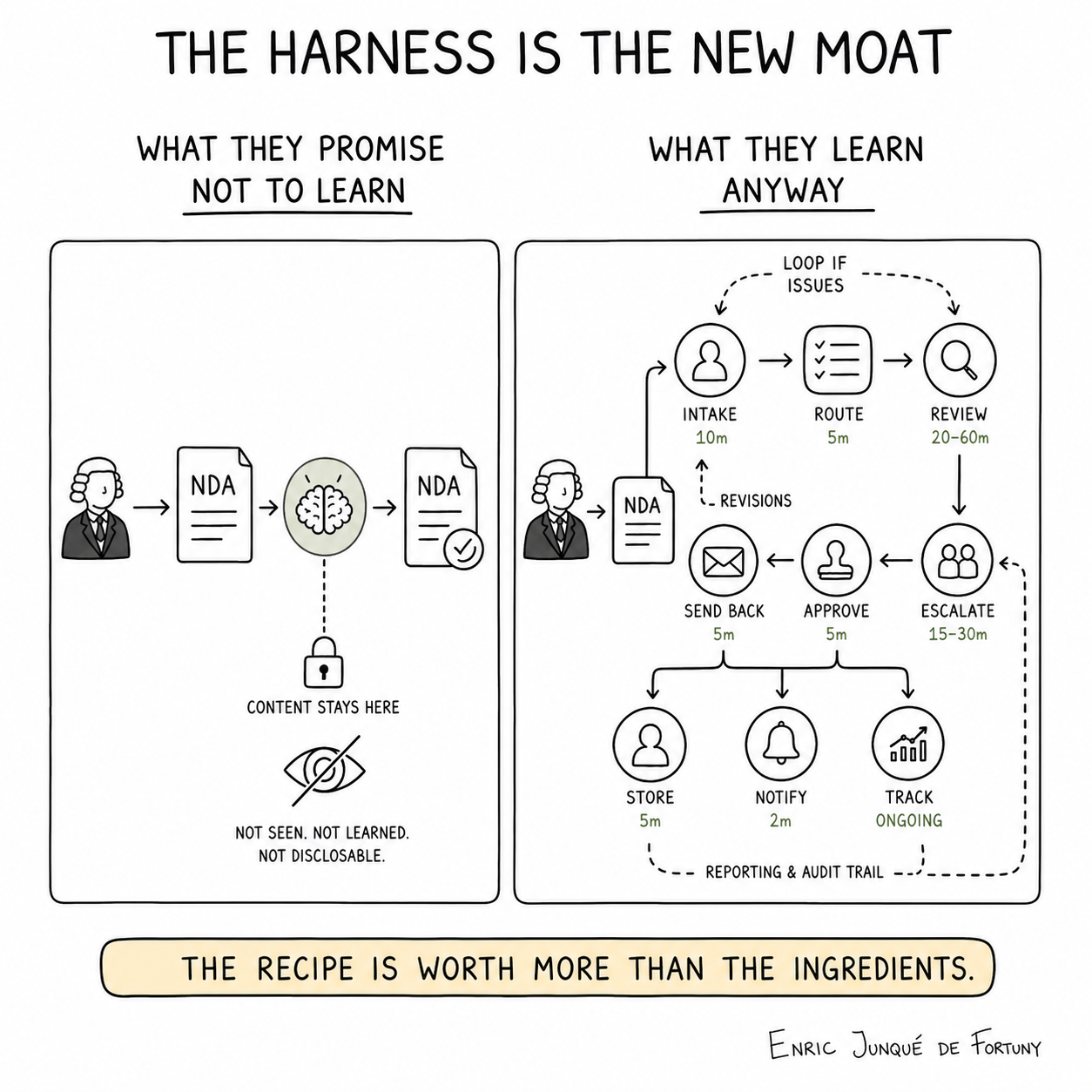
The harness is the new moat
"Competitive advantage is no longer the prompt. It is the trajectories your Harness captures." — Phil Schmid of Hugging Face, January 2026:
A trajectory is a structured log of how an agent executed a task — what decisions it made, which tools it called, where it succeeded or failed. Each trajectory is training data for the evaluation framework, the workflow templates, the reward signals that shape future agent behaviour. By now, Harvey has 25,000 custom workflows built on trajectory data from hundreds of leading law firms — accumulated process knowledge, the externalised form of what senior lawyers do, made reproducible at scale.
Again, the only thing that survived the great wave of commodification in GenAI is the harness and its associated knowledge.
The build/buy/partner error
Law firms correctly classify AI models as non-strategic. Then they assumed partnering on AI models means the entire capability was non-strategic. I'm arguing that, maybe, they are the modern equivalent of Boeing who made the same move with composite manufacturing on the 787. They classified it as adjacent, outsourced to Japanese heavies, and discovered too late that composites encode structural knowledge. This turned out to be a strategic mistake and Boeing is now spending billions to rebuild internally.
To be clear: I'm not saying that these tools aren't valuable - they are. The question is whether firms have correctly classified the capability they're outsourcing. In build / buy / partner terms: 𝘢𝘳𝘦 𝘺𝘰𝘶 𝘱𝘢𝘳𝘵𝘯𝘦𝘳𝘪𝘯𝘨 𝘰𝘯 𝘵𝘦𝘤𝘩𝘯𝘰𝘭𝘰𝘨𝘺, 𝘰𝘳 𝘢𝘳𝘦 𝘺𝘰𝘶 𝘰𝘶𝘵𝘴𝘰𝘶𝘳𝘤𝘪𝘯𝘨 𝘺𝘰𝘶𝘳 𝘰𝘳𝘨𝘢𝘯𝘪𝘻𝘢𝘵𝘪𝘰𝘯𝘢𝘭 𝘭𝘦𝘢𝘳𝘯𝘪𝘯𝘨? Harvey accumulates operational intelligence at unprecedented scale through their Usage Data policy and internal plumbing machinery.
As I was about to post this, a project called Mike appeared on GitHub (April 29th 2026). Built by Will Chen, a former BigLaw attorney, Mike is an open-source legal AI platform: self-hostable, AGPL-3.0, explicit about being a Harvey/Legora alternative. It reached 1,200 stars in 72 hours from a Hacker News front page. But will it be enohttps://github.com/willchen96/mikeugh? For now it doesn't have Westlaw, LexisNexis, etc but I believe it's a step in the right direction for any organization willing to gain an edge.
Two things to do now
- Audit your Usage Data exposure. Re-read the terms with this framing. What does your vendor capture about how you work, not just what you work on? What are their permitted uses of that data?
- Treat your workflow architecture as an asset. The specific way your firm structures agentic tasks — the prompt chains, the evaluation criteria, the human-in-the-loop checkpoints — is protectable intellectual property. Document it, and don't let it exist only inside a vendor's platform.
Member discussion